Pipedream links Global Phasing's main packages in a stepwise and essentially linear workflow:
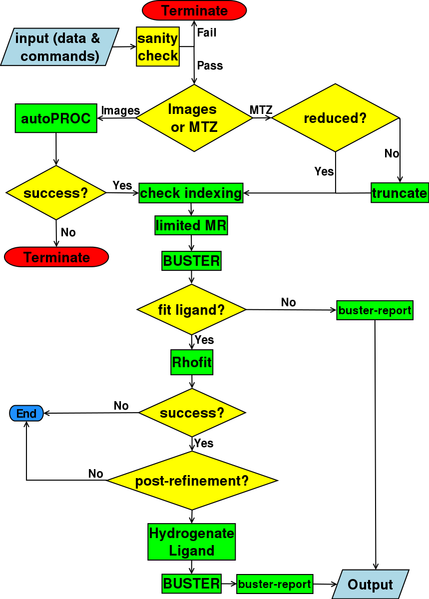
The scenario for which Pipedream has been designed, typical for a fragment screening regime, is that you have lots of crystals of your particular target protein from which you will collect x-ray data and solve the structures, both "apo" and soaked with potential ligands.
The main assumption, implicit from the above scenario, made by Pipedream is that the only significant difference between the structures in these experiments will be the presence/absence and nature of a bound ligand. Critically, Pipedream imposes and enforces a requirement that the space group of the experimental data must be the same as the reference structure, as do the cell dimensions (within limits due to inevitable crystal variability and non-isomorphism).
The required input data for pipedream are:
Pipedream is designed to be run in the background or submitted through a batch queue system. As such, it does not write anything to standard output. ALL of the output from Pipedream and from the separate packages that it calls is written into a new, clean directory, which MUST be specified on the command line.
All output is written in the defined (root) directory as follows:

In addition, Pipedream writes its own information and also collates, summarizes and tabulates the main information from each of the individual stages in the file summary.out, which should be the first file to look at.